Built for the AI and digital-twin era
One self-hosted engine unifying graph, time-series, geospatial, vector and full-text data — model real-world systems, query them at any point in time, and let AI agents query them directly.
Featured deployments

By industry




By capability
Digital twins & IoT
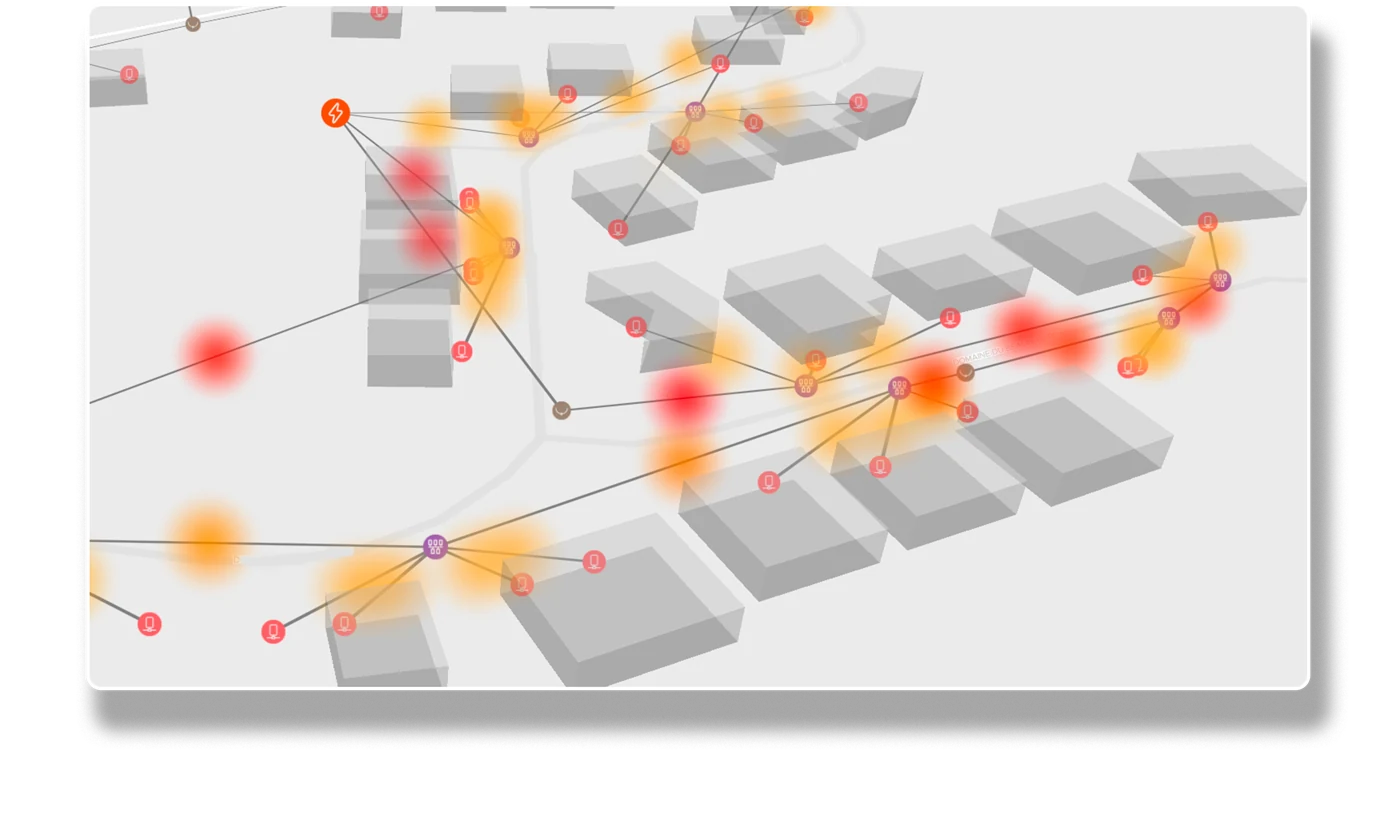
The problem. Modelling a real-world system means joining its structure, sensor streams and geography — usually three databases that never quite line up.
Why GreyCat. Assets, their time-series and their location live in one graph and one transaction — model a system once, then run simulations on the same data.
Proof. Kopr, a national electricity-grid digital twin on GreyCat, models ~1,000,000 grid assets and 330,000 delivery points, ingesting ~45 billion meter readings a year with continuous machine learning.
Knowledge graphs & GraphRAG
The problem. RAG built on vector similarity alone loses the relationships between entities — and stitching a graph DB, vector DB and keyword index together is brittle and slow.
Why GreyCat. Graph, vector and full-text search live in one store, with a built-in MCP server so AI agents query entities, relationships and embeddings directly — no glue code.
Result. Point-in-time-correct retrieval that grounds LLM answers in the facts and the connections between them.
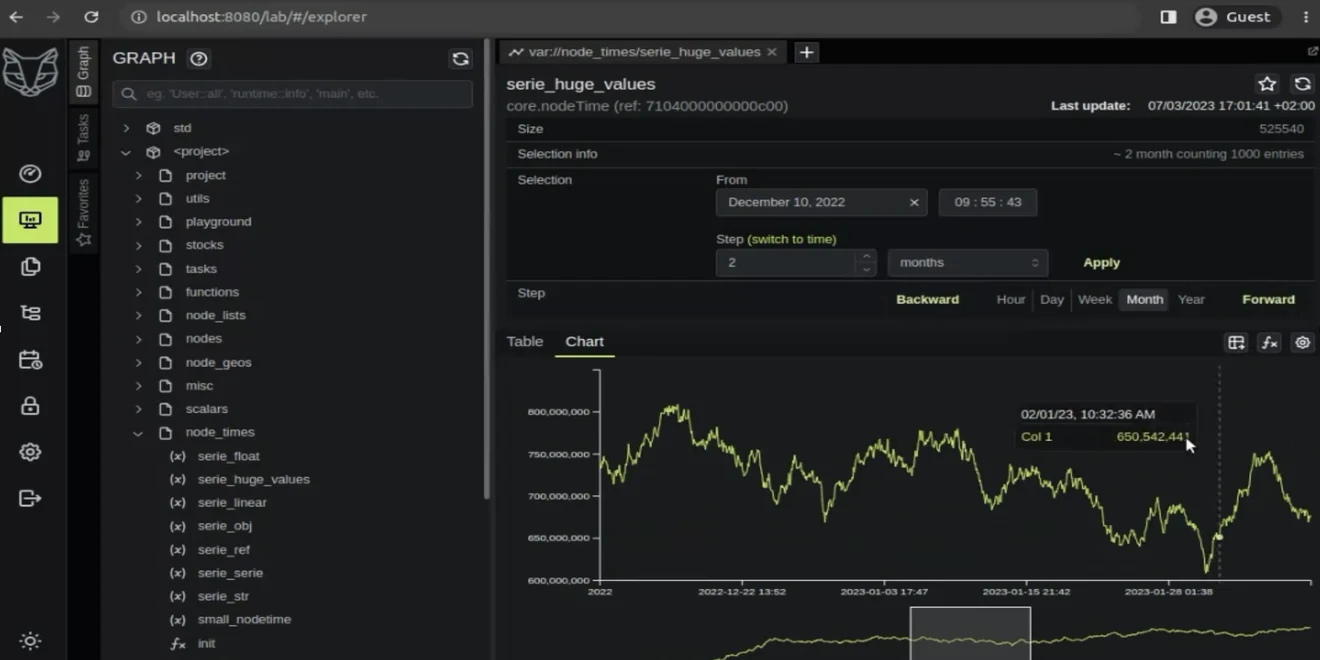
Real-time temporal analytics
The problem. Answering "what did this look like at that exact moment?" across billions of events usually means heavy ETL and pulling raw data out before you can analyze it.
Why GreyCat. As-of queries, server-side sampling, streaming statistics and FFT run inside the engine over billions of nodes — the computation goes to the data, not the other way around.
Result. Interactive temporal analytics with no separate analytics cluster to feed.
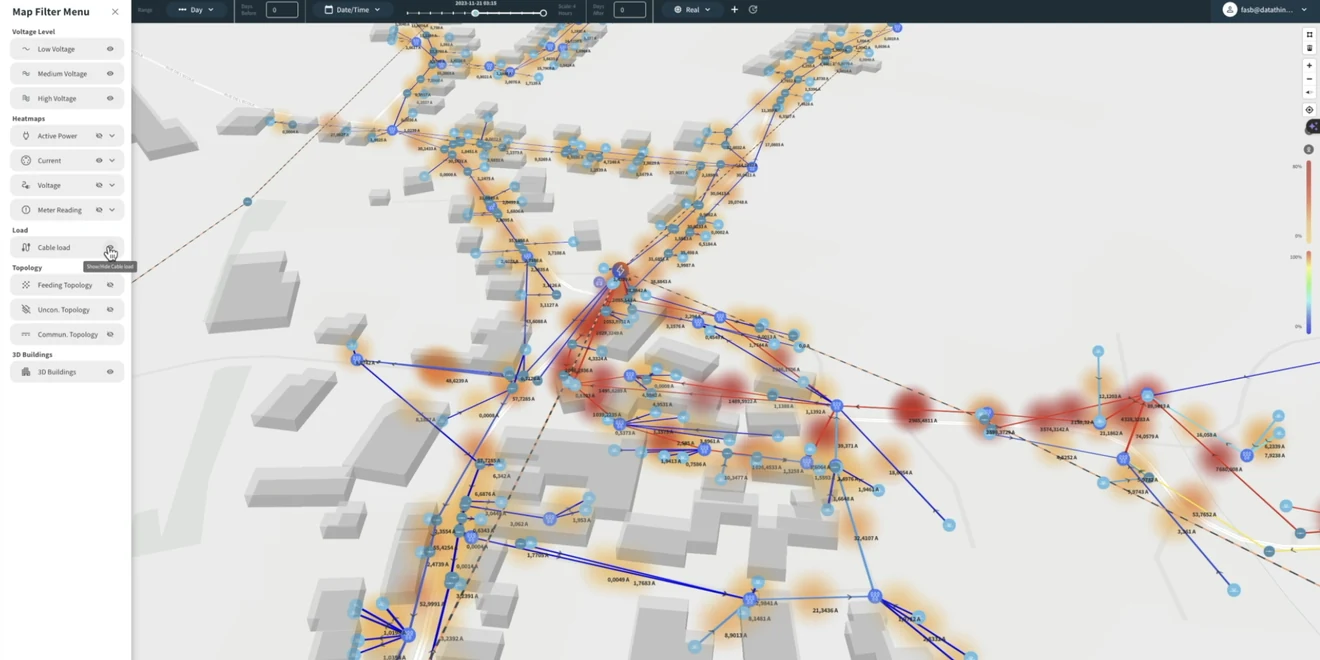
Industrial & IIoT
The problem. Industrial data is locked behind OPC-UA, MQTT and Kafka, often at the edge — and regulated sites can't ship it to a cloud they don't control.
Why GreyCat. Native OPC-UA, MQTT and Kafka connectors, edge deployment on commodity and ARM hardware, and full data sovereignty — the database runs where the data is.
Result. A single binary that ingests from plant floor to cloud, with no data leaving regulated infrastructure.
Document & semantic search
The problem. Good search needs both keyword precision and semantic recall — yet most stacks bolt a vector DB and an external embedding API onto a keyword engine, multiplying cost, latency and data sent outside.
Why GreyCat. Hybrid BM25 + vector search with on-device embeddings, in one engine, so documents and the search index never leave your deployment.
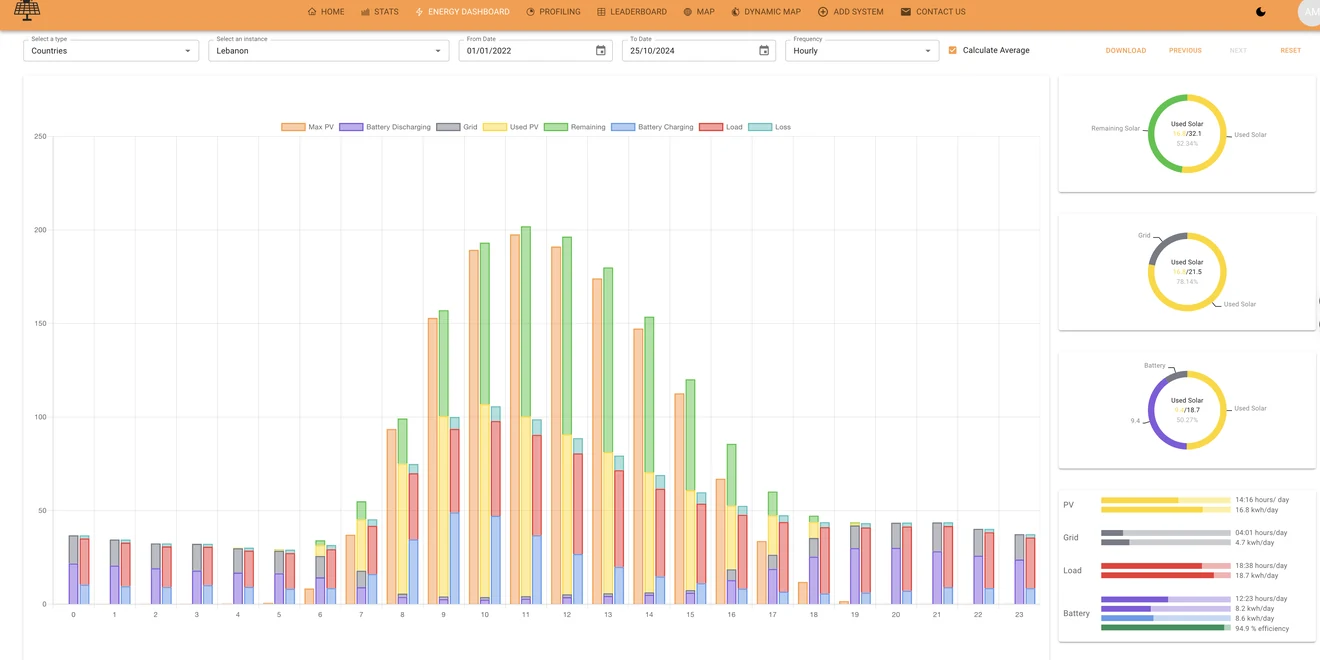
Solar simulation & mapping
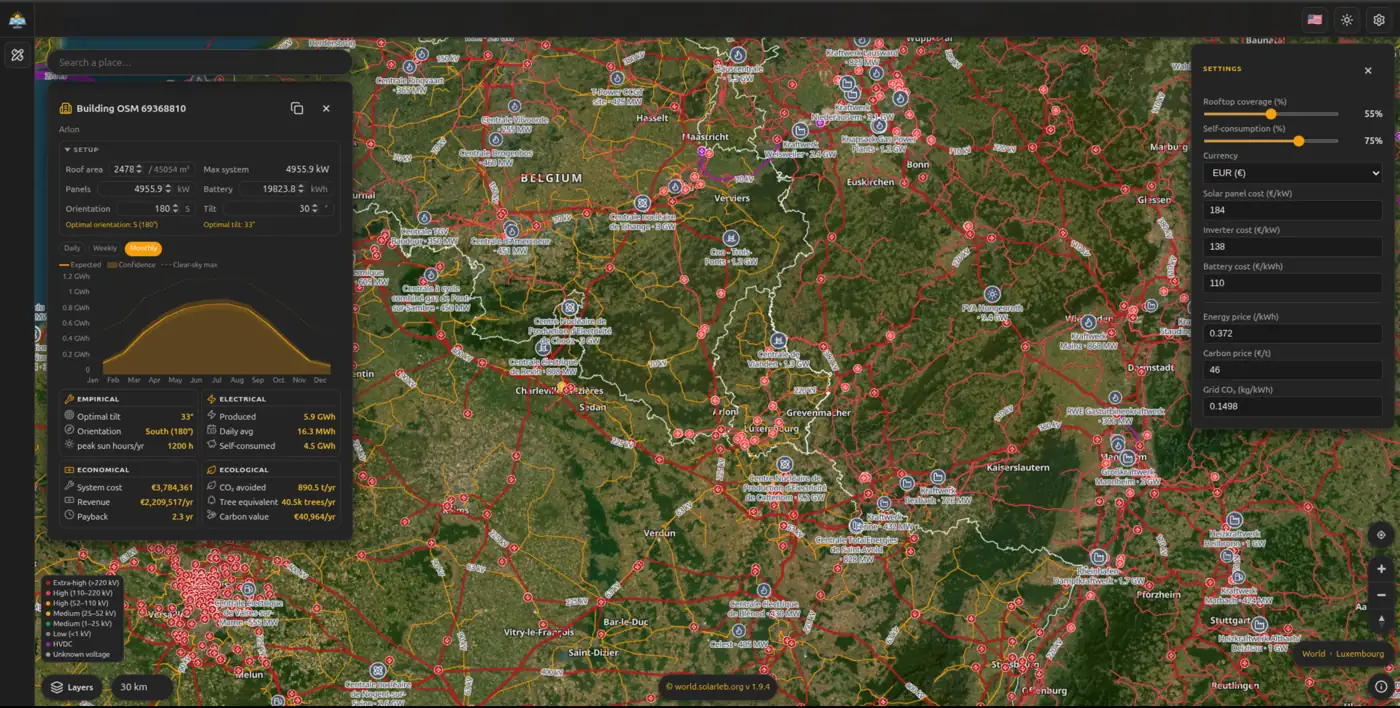
The problem. Planning solar at planetary scale means combining building footprints, rooftop geometry, terrain and irradiance for the entire world — geospatial and time-series data that is too large and scattered to query together.
Why GreyCat. Geospatial nodes, time-series irradiance and graph-linked assets live in one engine, so you can map every building on Earth and simulate its solar potential without a separate GIS stack.
Proof. Solar World maps the world's infrastructure building by building and simulates rooftop solar potential — running entirely on GreyCat.